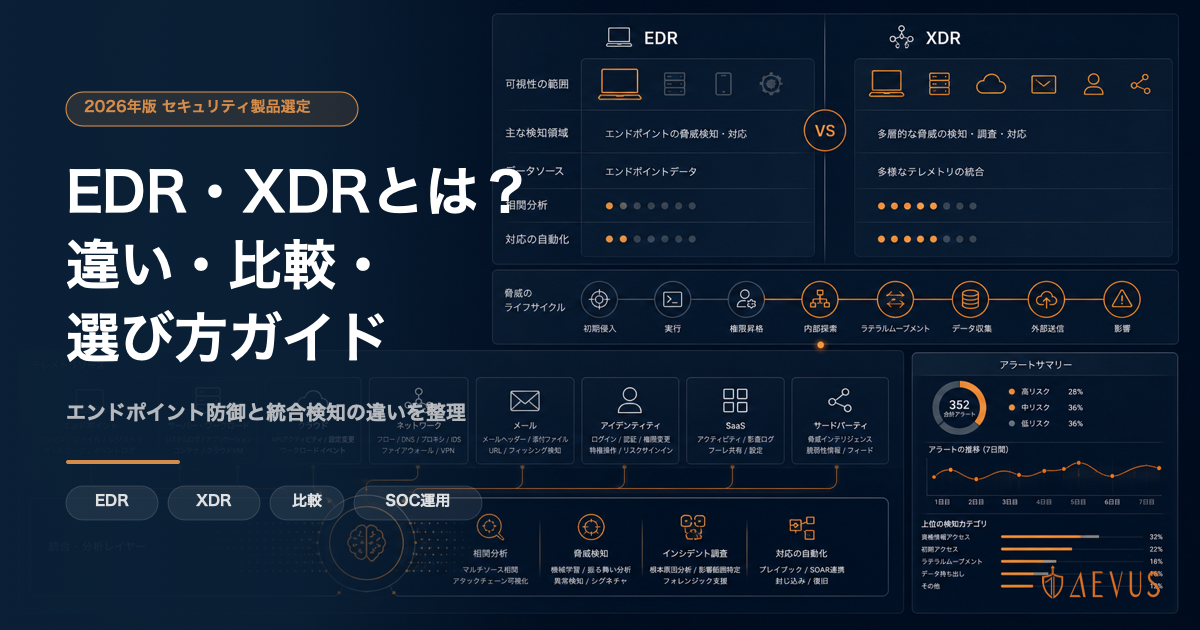
サイバー攻撃の高度化・巧妙化が止まらない現在、24時間365日の脅威監視体制を自社だけで維持することは、中堅・大手企業にとっても現実的でなくなりつつあります。経済産業省の「サイバーセキュリティ経営ガイドライン Ver.3.0」でも、インシデント検知・対応体制の外部活用が明示的に推奨されており、SOC(Security Operations Center)サービスの外部委託を検討するCISOやIT部門長が急増しています。一方で、「価格が不透明」「どのベンダーを選べばよいか分からない」「内製かアウトソースかで意思決定できない」という声も後を絶ちません。
本記事では、SOCサービスの種類と2026年時点の現実的な価格帯を整理した上で、国内ベンダーを選定する際に外せない5つのポイント、MDRや内製SOCとの客観的な比較、実際の導入失敗事例と回避策、そして最終判断に使える選定チェックリストを体系的にまとめました。SOC体制の整備・刷新を検討しているセキュリティ担当者の意思決定を加速するための実践的なガイドとしてご活用ください。
SOCサービスの種類と価格帯【2026年版】
SOCサービスといっても、提供範囲・技術スタック・対応深度によって大きく4つの類型に分かれます。自社のセキュリティ成熟度・予算・リスク許容度に応じて最適な類型が異なるため、まず全体像を俯瞰することが重要です。
種別 | 特徴 | 初期費用(目安) | 月額費用(目安) | 向いている企業 |
|---|---|---|---|---|
マネージドSIEM | SIEMプラットフォームの運用をベンダーに委託。ログ収集・相関分析・アラート通知が中心。対応(レスポンス)は自社が担う。 | 50万〜200万円 | 30万〜150万円 | 社内にセキュリティエンジニアが在籍しており、アラートの初動対応は自社で行えるが、SIEMの構築・チューニング工数を削減したい企業 |
MDR(Managed Detection & Response) | 検知(Detection)に加え、封じ込め・隔離などの初動対応(Response)までベンダーが実施。EDR/NDRと統合されたケースが多い。 | 100万〜500万円 | 80万〜400万円 | エンドポイント・ネットワーク双方の脅威に即時対応したい企業。インシデント発生時の初動対応リードタイムを最小化したいケース。 |
フルアウトソーシングSOC | 監視・検知・トリアージ・エスカレーション・フォレンジック支援まで一気通貫で委託。専任アナリストチームが担当。 | 200万〜800万円 | 150万〜600万円 | 社内セキュリティ人材が不足しており、SOC機能をまるごと外部化したい大手・中堅企業。 |
SOC as a Service(クラウド型) | クラウドネイティブなプラットフォームを活用したサブスクリプション型。契約〜稼働開始までが短期間(数週間〜2か月程度)。 | 0〜50万円 | 20万〜120万円 | 初期投資を抑えてスモールスタートしたい中堅・中小企業。 |
国内SOCサービスの選び方 5つのポイント
ポイント1:監視範囲とカバレッジの明確性
SOCサービスの契約で最初に確認すべきは「何を・どこまで監視するか」の定義です。クラウド環境(AWS・Azure・Google Cloud)、オンプレミスサーバ、エンドポイント(PC・モバイル)、OT/ICSネットワーク、SaaSアプリケーション(Microsoft 365・Salesforceなど)のうち、どのレイヤーがスコープに含まれるかをSoW(作業範囲記述書)レベルで明文化する必要があります。特に2026年時点では、クラウドネイティブの脅威検知(CSPM連携、クラウドログ分析)に対応しているかどうかがベンダー選定の重要な差別化ポイントになっています。
ポイント2:対応速度SLAと実績の検証
SOCサービスの契約書に「アラート検知後30分以内にエスカレーション」と記載されていても、実際の平均対応時間(MTTD・MTTR)が数時間に及ぶケースは珍しくありません。契約前に、直近12か月のMTTD・MTTRの実績値を書面で提示させることを強く推奨します。業界標準として、金融機関や重要インフラでは「MTTD 15分以内・MTTR 1時間以内」が求められるケースが増えています。
ポイント3:国内での導入実績と業界知識
グローバルSOCベンダーの中には、日本語対応が限定的であったり、日本固有の規制(個人情報保護法・金融商品取引法・FISC安全対策基準など)や商習慣への理解が浅いケースがあります。評価の際は、同業界での国内導入実績を具体的なケーススタディとして提示できるかを確認してください。
ポイント4:レポートの品質と経営層への説明可能性
SOCサービスから提供される月次・週次レポートは、単なる「アラート件数の集計」ではなく、経営層やボードへのリスク報告に活用できる質が求められます。具体的には、攻撃トレンドの分析、自社環境固有のリスク評価、改善推奨事項(Recommendation)、KPI/KRIの推移が含まれているかを確認してください。
ポイント5:拡張性とビジネス変化への追従力
企業のIT環境は常に変化します。M&Aによる子会社・関連会社の監視対象追加、クラウドへの移行加速、新たなSaaSツールの導入など、SOCサービスがこれらの変化に柔軟に対応できるかどうかは、長期契約では特に重要な評価ポイントです。
SOCサービス vs MDR vs 内製SOC — 徹底比較
評価軸 | 外部委託SOCサービス | MDR | 内製SOC |
|---|---|---|---|
初期コスト | 中(50万〜800万円) | 中〜高(100万〜500万円) | 非常に高(2,000万〜1億円超) |
ランニングコスト | 月額30万〜600万円 | 月額80万〜400万円 | 年間5,000万〜3億円(人件費含む) |
稼働開始までの期間 | 1〜3か月 | 2週間〜2か月 | 6か月〜2年 |
24時間365日対応 | 標準提供 | 標準提供 | 人員確保が必要(困難なケース多い) |
インシデント対応(Response) | エスカレーションまで(対応は自社) | 封じ込め・隔離まで実施 | 自社で全対応 |
最新脅威インテリジェンス | ベンダー提供(品質に差あり) | 高品質(EDRベンダーの脅威情報と統合) | 自社で収集・維持が必要 |
セキュリティ人材依存リスク | 低(ベンダーが採用・育成) | 低 | 高(人材離職で機能停止リスク) |
SOCサービス導入の失敗事例と回避策
失敗事例1:アラート過多でSOC機能が形骸化
事例の概要:国内製造業A社がマネージドSIEMサービスを導入した際、初期チューニング不足により月間10万件超のアラートが発生。担当者がアラートの確認・対応に追われ、本当に重要なインシデントの見落としが発生した。
回避策:本番稼働前の「チューニング期間(通常1〜3か月)」を契約に明記し、誤検知(False Positive)率の削減目標をKPIとして設定する。
失敗事例2:クラウド環境が監視対象外でインシデント未検知
事例の概要:金融系スタートアップB社が既存のオンプレ向けSOCサービスを継続しながらAWS環境を急拡大した結果、AWSのCloudTrailログが監視対象外となっており、IAMの不審な権限昇格を3週間検知できなかった。
回避策:新規クラウドサービスの導入時には、セキュリティチームとSOCベンダーへの事前通知を義務付ける社内ルールを策定する。
失敗事例3:インシデント発生時の役割分担が不明確で対応が遅延
事例の概要:小売業C社でランサムウェア感染が発生した際、SOCベンダーからエスカレーションを受けた担当者が不在(深夜)であり、初動対応が約4時間遅延した。その間にランサムウェアが社内ネットワークを横断し、被害が拡大した。
回避策:インシデント対応プレイブック(Runbook)を契約前に共同で作成し、「誰が・何時間以内に・何をするか」を深夜・休日も含めて明文化する。
失敗事例4:ベンダーロックインで乗り換えコストが膨大に
事例の概要:大手製造業D社が3年間利用したSOCサービスの更新時に、他ベンダーへの移行を検討したところ、ベンダー独自フォーマットで蓄積されたログデータや検知ルールのエクスポートが困難で、移行コストが当初見積もりの5倍に膨らんだ。
回避策:契約書に「サービス終了時・移行時のデータエクスポート保証(形式・期間・費用)」を明記する。
SOCサービス選定チェックリスト
- 監視スコープの明文化:監視対象(オンプレ・クラウド・エンドポイント・OT)が契約書・SoWに具体的に列挙されているか。
- SLAの具体性:MTTD・MTTRの数値目標が設定されており、SLA違反時のペナルティ条項が含まれているか。
- 実績の提示:同業界・同規模の国内導入事例(匿名可)を具体的に提示できるか。
- サンプルレポートの確認:月次・週次レポートのサンプルを事前に確認し、経営層報告に使えるレベルの内容か評価したか。
- インシデント対応プレイブック:深夜・休日を含む緊急連絡フローが文書化されており、自社との役割分担が明確化されているか。
- チューニング計画:本番稼働前のチューニング期間・誤検知率削減目標が契約に含まれているか。
- クラウド対応:利用中の主要クラウドサービスのログ監視に対応しているか。
- データポータビリティ:契約終了・移行時のログデータエクスポート条件が明記されているか。
- 拡張性の確認:監視対象デバイスの追加・削除、新規ログソースの追加に要する手続き・期間・追加費用が明示されているか。
- 訓練・レビューの仕組み:年次のインシデント対応訓練実施やサービススコープの定期見直しがサービスに含まれているか。
よくある質問(FAQ)
Q. SOCサービスとMDRの違いは何ですか?
A. SOCサービスは脅威の監視・検知・エスカレーションまでを提供するサービスの総称であり、インシデントへの対応(封じ込め・隔離)は自社が行うモデルが主流です。一方、MDR(Managed Detection & Response)は検知に加えて、エンドポイントの隔離や悪意あるプロセスの停止といった初動対応(Response)までベンダーが実施します。自社にインシデント初動対応の担当者を置けない場合はMDRが、包括的な監視体制と経営へのレポーティングを重視する場合はフルアウトソーシングSOCが向いています。
Q. 中小企業でもSOCサービスを導入できますか?
A. はい、可能です。SOC as a Service(クラウド型)の普及により、月額20万円台からSOC機能を利用できるサービスが増えています。従業員100名未満の企業でも、クラウドネイティブなSIEMと脅威インテリジェンスを組み合わせたサービスをスモールスタートで導入した事例は数多くあります。
Q. SOCサービスの契約期間はどのくらいが一般的ですか?
A. 国内では1年契約または3年契約が主流です。3年契約は月額費用が10〜20%程度割引されるケースが多い反面、途中解約が困難なリスクがあります。初めてSOCサービスを外部委託する場合は、1年契約でスタートし、チューニング完了後のサービス品質を実際に評価してから長期契約に移行することを推奨します。
Q. SOCサービスの導入で個人情報・機密データの漏洩リスクはありませんか?
A. SOCサービスでは、通信ログ・イベントログ・端末情報などをベンダーが処理するため、情報管理上のリスクは正当な懸念事項です。対策として、①契約書に守秘義務・データ保護条項を明記する、②ログデータの保管場所(国内データセンター限定か否か)を確認する、③ベンダーのISO 27001認証・SOC 2 Type II報告書を確認する、の3点を必ず実施してください。
Q. SOCサービスの導入後、自社に残るべき作業・体制は何ですか?
A. SOCを外部委託しても、以下の機能は自社に残すことが推奨されます。①SOCベンダーの窓口となるセキュリティ担当者(1〜2名)の設置、②インシデント発生時の最終意思決定(業務停止判断・経営報告)、③ベンダーからのエスカレーションを受けた際の実際の対応、④年次のセキュリティポリシー見直しとリスク評価。
まとめ
SOCサービスの外部委託は、セキュリティ人材不足と攻撃の高度化が加速する2026年においては、多くの企業にとって最も現実的かつ効果的な選択肢のひとつです。本記事で解説した「監視範囲・SLA・国内実績・レポート品質・拡張性」の5つのポイントと10項目のチェックリストを活用し、自社のリスク環境・ビジネス要件に最適なSOCサービスパートナーを選定してください。
AEVUSのSOCサービス
AEVUSは、国内トップクラスのサイバーセキュリティ専門家チームが提供する、高品質なSOC・MDRサービスを展開しています。オンプレミスからマルチクラウド環境まで一元的に監視し、24時間365日の脅威検知と日本語によるリアルタイム対応サポートを提供します。まずはお気軽にお問い合わせください。
SOCサービス導入でよくある失敗事例と回避策
失敗事例1:SLAの数字だけを信じて実態を確認しなかった
「アラート検知後15分以内にエスカレーション」というSLAを契約したにもかかわらず、実際の運用では深夜帯のアラートが翌朝まで放置されていたケースがあります。SLAは「平均値」であることが多く、ピーク時・深夜帯・休祝日の実態が乖離しているベンダーが存在します。回避策:契約前に直近12ヶ月のMTTD(平均検知時間)・MTTR(平均対応時間)の実績値を時間帯別・曜日別に書面で提出させます。また、契約書にSLA未達時のペナルティ条項(利用料の減額・解約権)を明記することを要求します。
失敗事例2:監視対象範囲の「穴」を把握しないまま契約した
クラウド環境(AWS・Azure)が監視スコープに含まれていると思っていたが、契約書を読むと「オンプレミス環境のみ」が対象だったという事例があります。また、SaaSアプリケーション(Microsoft 365・Salesforce)のログがSOCのSIEMに取り込まれておらず、クラウドからの侵害を検知できなかったケースも報告されています。回避策:SoW(作業範囲記述書)に監視対象の環境・ログソース・エンドポイント数を具体的に列挙させます。「クラウド環境含む」という曖昧な記載ではなく、「AWSアカウント○個のCloudTrailログ・VPCフローログ・GuardDutyアラートを収集・監視する」という粒度で明文化します。
失敗事例3:アナリストが常駐せずツールの自動アラートのみだった
「24時間365日監視」と謳っていたSOCサービスの実態が、SIEMの自動アラートをメールで転送しているだけで、セキュリティアナリストによるトリアージ・分析は平日日中のみという事例があります。深夜に発生したランサムウェアの初期侵害を翌朝まで検知できず、感染が社内全域に拡大しました。回避策:「24時間365日、セキュリティアナリストが常駐して監視している」ことを明示的に確認します。具体的には「深夜2時にアラートが上がった場合、何分以内に誰が初動対応を開始するか」のプロセスを説明させます。
失敗事例4:ベンダー変更が困難な「ロックイン」状態になった
SOCサービスを3年間利用した後にベンダー変更を検討したところ、ログデータの移管・過去のインシデント記録のエクスポート・SIEMのルール設定の引き継ぎが困難で、事実上の囲い込みが発生したケースがあります。回避策:契約時にデータポータビリティ条件(ログデータのエクスポート形式・期間・費用)を明確にします。SIEMのルールセットやプレイブックのドキュメントをベンダーから定期的に共有させる条件を入れておくことも有効です。
失敗事例5:インシデント発生時の「役割分担」が未定義だった
SOCベンダーからエスカレーション連絡が来た際、「自社側の誰が何をするか」が決まっておらず、担当者が右往左往してインシデント対応が大幅に遅延したケースがあります。SOCサービスは「検知・通知」までが基本サービスであり、その後の「判断・封じ込め・復旧」は自社側の責任であるケースが多いためです。回避策:SOC導入と同時に、自社のインシデント対応フロー(エスカレーション先・意思決定権者・初動対応手順)を整備します。年1回以上、SOCベンダーを含めたインシデント対応訓練(テーブルトップ演習)を実施して連携を確認します。
契約前に確認すべき8つのチェックリスト
確認項目 | 確認内容 | 判断基準 |
|---|---|---|
監視範囲 | クラウド・オンプレ・エンドポイント・SaaSのカバレッジ | 自社の全ログソースがスコープに含まれているか書面確認 |
SLA実績 | 過去12ヶ月のMTTD・MTTR実績値(時間帯別) | 深夜・休日でも目標値を達成しているか |
アナリスト体制 | 常駐アナリスト数・担当者の資格・ローテーション | 24時間365日、有資格者が常駐しているか |
レポート品質 | サンプルレポートの取り寄せ・項目確認 | 経営報告に使えるエグゼクティブサマリーがあるか |
国内実績 | 同業界・同規模の国内導入事例の提示 | 具体的な事例(課題・効果)が説明できるか |
データポータビリティ | 契約終了時のログデータ移管・エクスポート条件 | 合理的なコスト・期間でデータを取り出せるか |
インシデント対応範囲 | 検知後のレスポンス(封じ込め・隔離)の対応範囲 | 自社がどこまで担当するかを明文化 |
SLA未達ペナルティ | SLA未達時の補償条件 | 利用料減額・解約権などが契約書に明記されているか |
SOCサービスを最大限活用するための運用Tips
Tip 1:定例レビュー会議を月次で設定する
SOCベンダーとの月次定例会議を設定し、前月のアラート件数・インシデントトレンド・検知した攻撃手法・改善推奨事項を確認します。会議に情報システム部門長または CISOが参加することで、SOCからの情報が経営判断に直結します。
Tip 2:SOCのルールチューニングに積極的に関与する
SIEMのアラートルールやホワイトリスト設定は、自社環境に合わせた継続的なチューニングが必要です。「誤検知が多い」「見落としがある」という状況を放置せず、四半期ごとにルールの見直しをベンダーと共同で実施します。チューニングの記録と変更理由を文書化することで、担当者が交代しても運用品質を維持できます。
Tip 3:脅威インテリジェンスの自社活用を促進する
SOCベンダーが保有する脅威インテリジェンス(攻撃グループのTTP・最新マルウェアのIOC等)を、自社のセキュリティポリシー見直しや従業員教育に活用します。「今この業界を狙っているランサムウェアグループはどこか」をSOCから定期的に共有してもらう運用を確立すると、経営層への説明材料にもなります。